Sentiment Analysis for Arabizi on Social Media
Author: Taha Tobaili, Knowledge Media Institute (KMi).
Supervisors: Miriam Fernandez and Harith Alani, KMi.
Sytem Developer: Chris Sanders, KMi.
Acknowledgments: Sanaa Sharafeddine, Rania Islambuli, Omar Farhat, and
Omar Osman, Lebanese American University,
Hazem El-Hajj, American University of Beirut, and Goran Glavaš, Universität Mannheim.
Introduction
Arabizi is the name given to a new social transcription of the spoken Arabic in Latin script. The term comes from the portmanteau of Araby (Arabic) and Englizi (English). It is an informal written language where Arabs transcribe their dialectal mother tongue in text using Latin alphanumeral instead of Arabic script. For example حبيبي Ḥabībī my-love could be transcribed as 7abibi in Arabizi.
Arabizi is extremely low resourced for Natural Language Processing (NLP), in this research we focus on resourcing Lebanese dialect Arabizi for sentiment analysis, an NLP classification task of text into classes of positive, negative, or neutral automatically. However the nature of the Arabizi scripture poses many challenges for sentiment classification, such that it is highly sparse and codeswitched, meaning words could have a large number of forms, whether orthographic or morphologic, or mixed with words of other languages such as French or English.
Arabic is also a phonetically-rich language containing short and long vowels, soft and emphasised consonants, and guttural phonemes such that transcribing it in Latin script, a relatively phonetically-poor language, generates severe word ambiguities that it becomes difficult to transliterate to Arabic. For that, one Arabizi word could easily map to several Arabic words of different meanings. We appreciated the fact that Arabizi is a social language and resourced it independently without attempting to transliterate it to Arabic. Read more in-depth about the challenges of Arabizi for sentiment classification and transliteration in the link below.

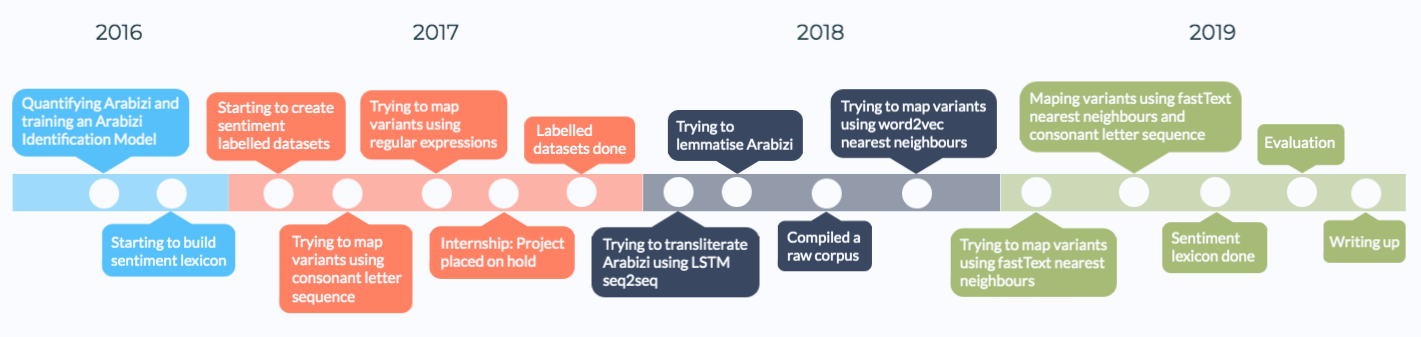
Timeline
We kicked off the research by a pilot study quantifying Arabizi on Twitter across two different Arab regions, and discovered language identification features that could be used in training a classifier to identify Arabizi from non-Arabizi text. From this point onwards, our goal was to create a new sentiment lexicon and evaluation datasets, however the main challenge was mapping sentiment words with their inflectional and orthographic variants. The deeper we ingressed into the study the more we realised how challenging this was. Hence the research was more applied than theoretical, we kept trying different approaches, failing relentlessly, but slowly paving the way for a sucessful approach at the end:
Presentation
I presented my work to the lab in May 2017 during the early stages of the PhD. In this talk I described some of the challenges for processing Arabizi and the development of the sentiment annotated dataset:
Resources
Arabizi Identification in Twitter Data (2016)
In this paper we present a pilot study about the percentage of Arabizi usage on Twitter across Lebanon and Egypt. We also describe our approach of training a classifier that identifies Arabizi from other Latin script languages.
This file contains two 5k tweets annotated datasets (Arabizi/Not Arabizi) from Lebanon and Egypt.
Discovering Orthographic and Morphological Variances in Low-Resourced Languages (2019)
We submitted an abstract of our work at EurNLP 2019 which proves the effectiveness of word embeddings onto the development of sentiment lexicons, especially in languages that lack a standard orthography such as Arabizi. We presented a summary of this work in the poster below:

SenZi: A Sentiment Analysis Lexicon for the Latinised Arabic (2019)
In this paper we present the outcomes of the work: SenZi, the new Lebanese dialect Arabizi sentiment lexicon, sentiment annotated datasets, and a Facebook corpus. We then detail our approach in expanding every sentiment word in SenZi to match with its inflectional and orthgraphic variants automatically using word embeddings jointly with a simple rule-based technique.
This file contains:
- SenZi: The original sentiment lexicon consisting of 2K sentiment words.
- Senzi Expanded: Orthographically and morphologically rich sentiment lexicon cosisting of 25K sentiment words.
- Datasets: Arabizi/Not-Arabizi 4.4K tweets, and sentiment (positive/negative) 1.6K tweets annotated datasets.
- Corpus: 1M Arabizi comments extracted from 47 public facebook pages.
- Embeddings: Word2vec and Fasttext word embeddings spaces trained on a filtered corpus.
PhD Thesis: Sentiment Analysis for the Low-Resourced Latinised Arabic (Arabizi) (2020)
Contains a detailed overview of the problem, linguistic nitty-gritty of Arabizi’s different transcriptions, literature review about several NLP tasks adressing Arabizi, development of the datasets and sentiment lexicon, and finally six lexical expansions to address the high lexical sparsity caused by the inconsistent orthography and rich morphology. This thesis sets the baseline of sentiment analysis for Arabizi without attempting to transliterate it to Arabic.
This file contains miscellaneous of resources that did not get published:
- Multi-dialect Twitter datasets from Qatar, Emirates, Saudi Arabia, Kuwait, Jordan, Lebanon, Egypt, Algeria, Morrocco.
- List of Arabic sentiment words with their Part of Speech tags and IPA transcriptions as well.
- List of Arabic Arabizi translation matrices.
- List of features used in the lexicon based approach (negations and stop words).
Lexical Induction of Morphological and Orthographic Forms for Low-Resourced Languages (2020)
An extension to the previous work, we reverse-engineer the lexical expansion approach over the original 2K sentiment SenZi words achieving a greater expansion of 171K words. Latinisation of non-Latin script languages is common across widely spoken languages as well. Our approach has the potential to induce morphologic and orthographic forms of Latinscript words for other languages that lacks a standard orthography.
This file contains the newly expanded sentiment lexicon: Senzi-Large - 171K words.
Appreciation
I would like to thank every individual who contributed to this project from producing datasets to developing and maintaining the data annotation system and especially my supervisors for their continuous guidance and support.
If you find the resources useful and would like to appreciate the work or have any question, please drop me an email.